Servidor de inferencias para LLaMA 3.1 405B
Empezaremos con un ejemplo básico en Python para probar nuestro modelo:
from vllm import LLM
# Load LLaMA 3.1 405B on 8 GPUs
llm = LLM("neuralmagic/Meta-Llama-3.1-405B-Instruct-FP8-dynamic", tensor_parallel_size=8)
print(llm.generate("What is the difference between fp8 quantization and int8 quantization?"))
Puedes ejecutar el script de Python. Si es la primera vez que lo ejecutas, tendrás que esperar a que el modelo se descargue y se cargue en la GPU, entonces recibirás una respuesta como esta:
FP8 (Floating-Point 8) and INT8 (Integer 8) are both quantization techniques used to reduce the precision of numerical values in deep learning models, but they differ in their representation and behavior.
**INT8 Quantization**
INT8 quantization represents numbers as 8-bit integers, which can take on values between -128 and 127 (or 0 and 255 for unsigned integers). This means that the precision of the numbers is limited to 8 bits, and any values outside this range are clipped or saturated.
INT8 quantization is a simple and widely used technique, especially for integer-based architectures like ARM and x86. Most deep learning frameworks, including TensorFlow and PyTorch, support INT8 quantization.
**FP8 Quantization**
FP8 quantization, on the other hand, represents numbers as 8-bit floating-point numbers, with 1 sign bit, 2 exponent bits, and 5 mantissa bits. This allows for a much larger dynamic range than INT8, with values that can be as small as 2^-14 or as large as 2^15.
FP8 quantization is a more recent development, and its main advantage is that it can provide better accuracy than INT8 quantization, especially for models that require a large dynamic range, such as those with batch normalization or depthwise separable convolutions. FP8 is also more suitable for models that are sensitive to quantization noise, like those with recurrent neural networks (RNNs) or long short-term memory (LSTM) networks.
**Key differences**
Here are the key differences between FP8 and INT8 quantization:
1. **Dynamic range**: FP8 has a much larger dynamic range than INT8, which means it can represent a wider range of values.
2. **Precision**: FP8 has a lower precision than INT8, with 5 mantissa bits compared to 8 bits for INT8.
3. **Behavior**: FP8 is more suitable for models that require a large dynamic range, while INT8 is better suited for models with smaller weights and activations.
4. **Hardware support**: INT8 is widely supported by most hardware platforms, while FP8 is still an emerging standard, with limited hardware support.
In summary, FP8 quantization offers better accuracy and a larger dynamic range than INT8 quantization, but it requires more sophisticated hardware support and may not be suitable for all models or applications.
El modelo LLaMA 3.1 405B ya ha sido cuantizado en fp8 para vLLM por Neural Magic, por lo que no necesitamos realizar la cuantización de nuevo. Simplemente cargamos el modelo cuantizado desde el Hub HuggingFace.
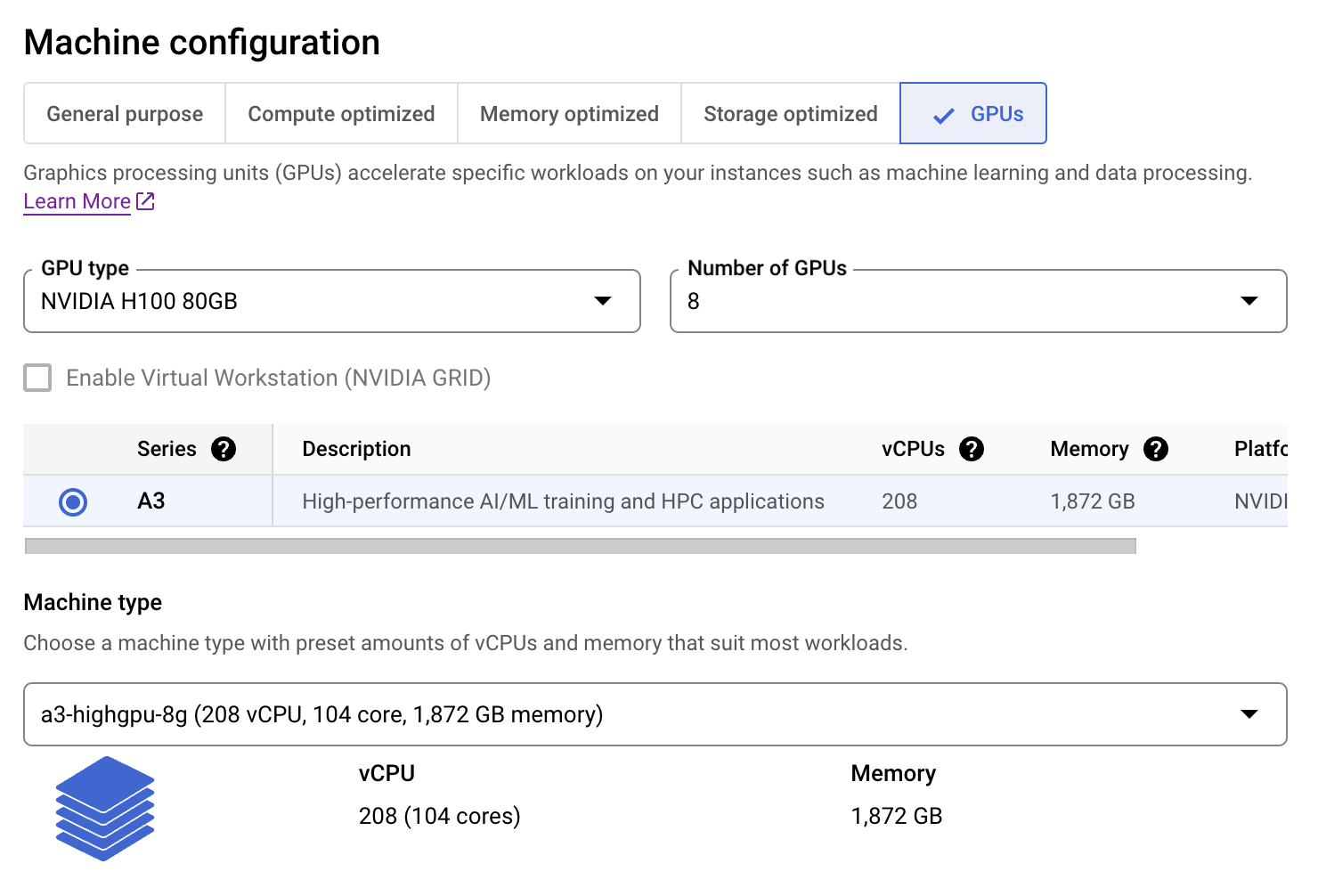
El parámetro tensor_parallel_size se establece en función del número de GPUs que poseamos en nuestra máquina.
Sin embargo, este sencillo script de Python no es un servidor de producción propiamente dicho. Ahora iniciaremos el servidor de inferencia para consumir muchas peticiones en paralelo y maximizar el rendimiento:
python -m vllm.entrypoints.openai.api_server \
--model neuralmagic/Meta-Llama-3.1-405B-Instruct-FP8-dynamic \
--tensor-parallel-size 8
Una vez cargado el modelo, puede iniciar un segundo terminal y realizar algunas peticiones:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "neuralmagic/Meta-Llama-3.1-405B-Instruct-FP8-dynamic",
"prompt": "Who are you?"
}'
I'm an artificial intelligence model known as Llama. Llama stands for "Large Language Model Meta AI."