











Use the best AI
engines without sacrificing data privacy.
user@local:~$
Fast and accurate AI models suited for production. Highly-available inference API leveraging the most advanced hardware.
NLP Cloud is HIPAA / GDPR / CCPA compliant, and working on the SOC 2 certification. We cannot see your data, we do not store your data, and we do not use your data to train our own AI models.
For critical security and privacy needs, or for performance reasons, you can deploy our models in-house on your own isolated servers. Our expert team is here to assist.
Use all NLP Cloud's AI models in 200 languages, thanks to our multilingual models and our multilingual addon.
Do not worry about DevOps or API programming and focus on text processing only. Deliver your AI project in no time.
Fine-tune your own models or upload your in-house custom models, and deploy them easily to production
NLP Cloud is an artificial intelligence platform that allows you to use the most advanced AI engines, and even train your own engines with your own data. This platform is focused on data privacy by design so you can safely use AI in your business without compromising confidentiality, and even deploy our AI models on-premise / at the edge. We offer both small specific AI engines and large cutting-edge generative AI engines so you can easily integrate the most advanced AI features into your application at an affordable cost.


NLP Cloud closely collaborates with NVIDIA in order to deliver state-of-the-art performance. Our generative AI engines are deployed on the most advanced NVIDIA GPUs in order to guarantee low latencies and affordable costs. You can also deploy our AI engines on your own on-premise NVIDIA GPUs.
NLP Cloud provides you with a simple and robust API.
Scalability and high availability are managed seamlessly by the platform.
Not sure how to correctly use generative AI and large language models? Our support team is here to advise!
See our client libraries on Github:





More details in the documentation.
"We spent a lot of energy fine-tuning our machine learning models, but we clearly underestimated the go-live process. NLP Cloud saved us a lot of time, and prices are really affordable."
"Our corporate policy does not allow us to use GPT-5 on OpenAI, so we use GPT-OSS 120B on NLP Cloud instead. Great thing is that it can be deployed on-premise, which is something we might consider in the future for privacy and compliance reasons."
"We had developed a working API deployed with Docker for our model, but we quickly faced performance and scalability issues. After spending weeks on this we eventually went for this cloud solution and we haven't regretted it so far!"
"We eventually gave up on fine-tuning LLaMA 3... We are now exclusively fine-tuning and deploying Dolphin on NLP Cloud and we are happy like this."
LAO (Laboratoire d'appareillage occulaire) is a French industrial laboratory making innovating lenses in order to cure specific eye diseases like the Lyell's syndrome.
LAO uses NLP Cloud classification API for automatic support tickets triage.
"Our collaboration with NLP Cloud has tremendously helped us increase our productivity and our patients satisfaction. We had the intuition that AI could help us but we had no idea how to implement it. NLP Cloud's expertise has been crucial."
Frédéric Baëchelé, CEO at LAO

| Use Case | Model Used | |
|---|---|---|
| Automatic Speech Recognition (speech to text): extract text from an audio or video file, with automatic language detection, automatic punctuation, and word-level timestamps, in 100 languages. | We use OpenAI's Whisper Large model. | Playground >> |
| Classification: send a piece of text, and let the AI apply the right categories to your text, in many languages. As an option, you can suggest the potential categories you want to assess. | We use GPT-OSS 120B, LLaMA 3.1 405B and an in-house NLP Cloud model called Fine-tuned LLaMA 3.3 70B. We also use the Bart Large MNLI Yahoo Answers and XLM Roberta Large XNLI by Joe Davison. | Playground >> |
| Chatbot/Conversational AI: discuss fluently with an AI and get relevant answers, in many languages. | We use GPT-OSS 120B, LLaMA 3.1 405B and in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3.3 70B. We also use Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. | Playground >> |
| Code generation: generate source code out of a simple instruction, in any programming language. | We use GPT-OSS 120B, LLaMA 3.1 405B and in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. | Playground >> |
| Dialogue Summarization: summarize a conversation, in many languages | We use Bart Large CNN SamSum by Philipp Schmid. | Playground >> |
| Embeddings: calculate embeddings in more than 50 languages. | We use several Sentence Transformers models like Paraphrase Multilingual Mpnet Base V2. | |
| Grammar and spelling correction: send a block of text and let the AI correct the mistakes for you, in many languages. | We use GPT-OSS 120B, LLaMA 3.1 405B and in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. | Playground >> |
| Headline generation: send a text, and get a very short summary suited for headlines, in many languages | We use T5 Base EN Generate Headline by Michal Pleban. | Playground >> |
| Intent Classification: understand the intent from a piece of text, in many languages. | We use GPT-OSS 120B, LLaMA 3.1 405B and in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. | Playground >> |
| Keywords and keyphrases extraction:extract the main keywords from a piece of text, in many languages. | We use GPT-OSS 120B, LLaMA 3.1 405B and an in-house NLP Cloud model called and Fine-tuned LLaMA 3.3 70B. | Playground >> |
| Language Detection: detect one or several languages from a text. | We use Python's LangDetect library. | Playground >> |
| Lemmatization: extract lemmas from a text, in many languages | All the large spaCy models are available. | |
| Named Entity Recognition (NER): extract structured information from an unstructured text, like names, companies, countries, job titles... in many languages. | We use GPT-OSS 120B, LLaMA 3.1 405B and an in-house NLP Cloud model called Fine-tuned LLaMA 3.3 70B. We also use all the large spaCy models. | Playground >> |
| Noun Chunks: extract noun chunks from a text, in many languages | All the large spaCy models are available. | |
| Paraphrasing and rewriting: generate a similar content with the same meaning, in many languages. | We use GPT-OSS 120B, LLaMA 3.1 405B and an in-house NLP Cloud model called Fine-tuned LLaMA 3.3 70B. | Playground >> |
| Part-Of-Speech (POS) tagging: assign parts of speech to each word of your text, in many languages | All the large spaCy models are available. | |
| Question answering: ask questions about anything, in many languages. As an option you can give a context so the AI uses this context to answer your question. | We use GPT-OSS 120B, LLaMA 3.1 405B and in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Roberta Base Squad 2 by Deepset, Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. | Playground >> |
| Semantic Search: search your own data, in more than 50 languages. | Create your own semantic search / RAG model out of your own domain knowledge (internal documentation, contracts...) and ask semantic questions on it. | Playground >> |
| Semantic Similarity: detect whether 2 pieces of text have the same meaning or not, in more than 50 languages. | We use Paraphrase Multilingual Mpnet Base V2. | Playground >> |
| Sentiment and emotion analysis: determine sentiments and emotions from a text (positive, negative, fear, joy...), in many languages. We also have an AI for financial sentiment analysis. | We use DistilBERT Base Uncased Finetuned SST-2, DistilBERT Base Uncased Emotion, and Finbert by Prosus AI. | Playground >> |
| Speech Synthesis (Text-To-Speech): convert text to audio | We use Speech T5 by Microsoft. | Playground >> |
| Summarization: send a text, and get a smaller text keeping essential information only, in many languages | We use GPT-OSS 120B, LLaMA 3.1 405B and in-house NLP Cloud models called ChatDolphin, and Fine-tuned LLaMA 3 70B. We also use Bart Large CNN by Meta, Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. | Playground >> |
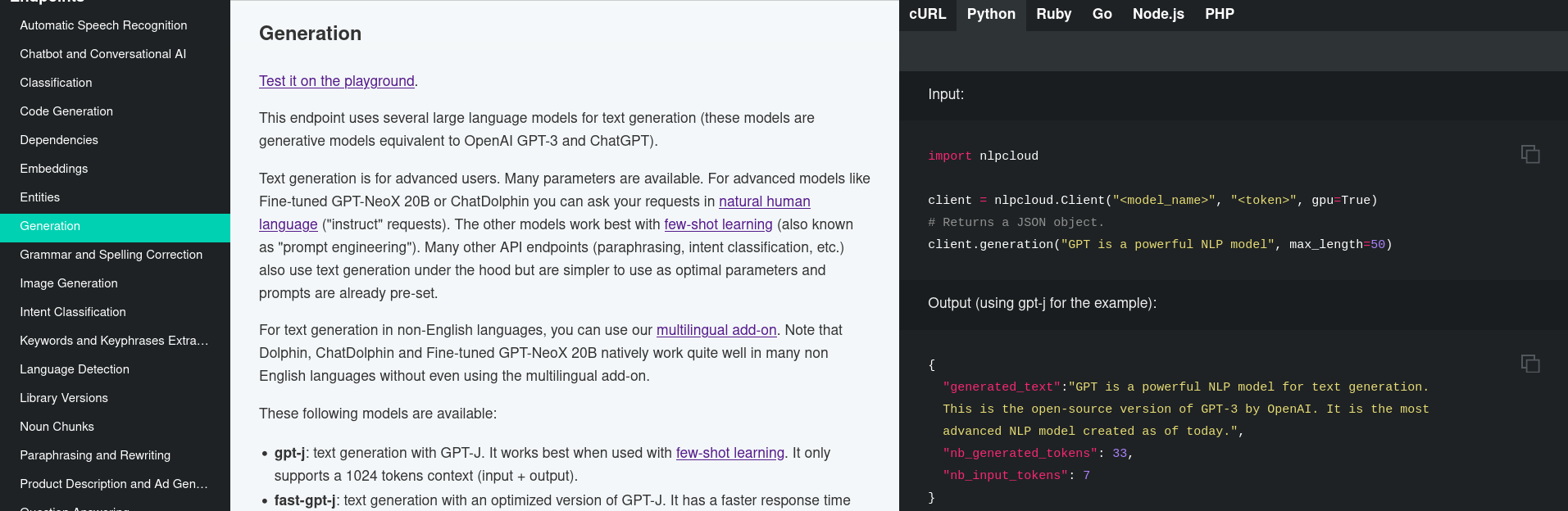
| Text generation: achieve all the most advanced AI use cases by either making requests in natural language ("instruct" requests) or using few-shot learning. | We use GPT-OSS 120B, LLaMA 3.1 405B and an in-house NLP Cloud model called ChatDolphin and Fine-tuned LLaMA 3.3 70B. We also use Dolphin Yi 34B by Eric Hartford, and Dolphin Mixtral 8x7B by Eric Hartford. You can also fine-tune your own text generation model for even better results. | Playground >> |
| Tokenization: extract tokens from a text, in many languages | All the large spaCy models are available. | |
| Translation: translate text in 200 languages with automatic input language detection. | We use NLLB 200 3.3B by Meta for translation in 200 languages. | Playground >> |
Looking for a specific use case or AI model that is not in the list above? Please let us know!
Most of our AI models can be deployed on your own servers.
This is the best solution for critical applications that require a high level of privacy like medical applications, financial applications... Our models do not require an internet connection.
It is also interesting in case of applications requiring a low latency, since you can make sure that your AI model is as close as possible to your end users.
Provisioning your own AI infrastructure can be challenging. That is why our engineers can assist you during the deployment process if needed.
You can also fine-tune your own models on NLP Cloud, and then deploy them on your own servers.


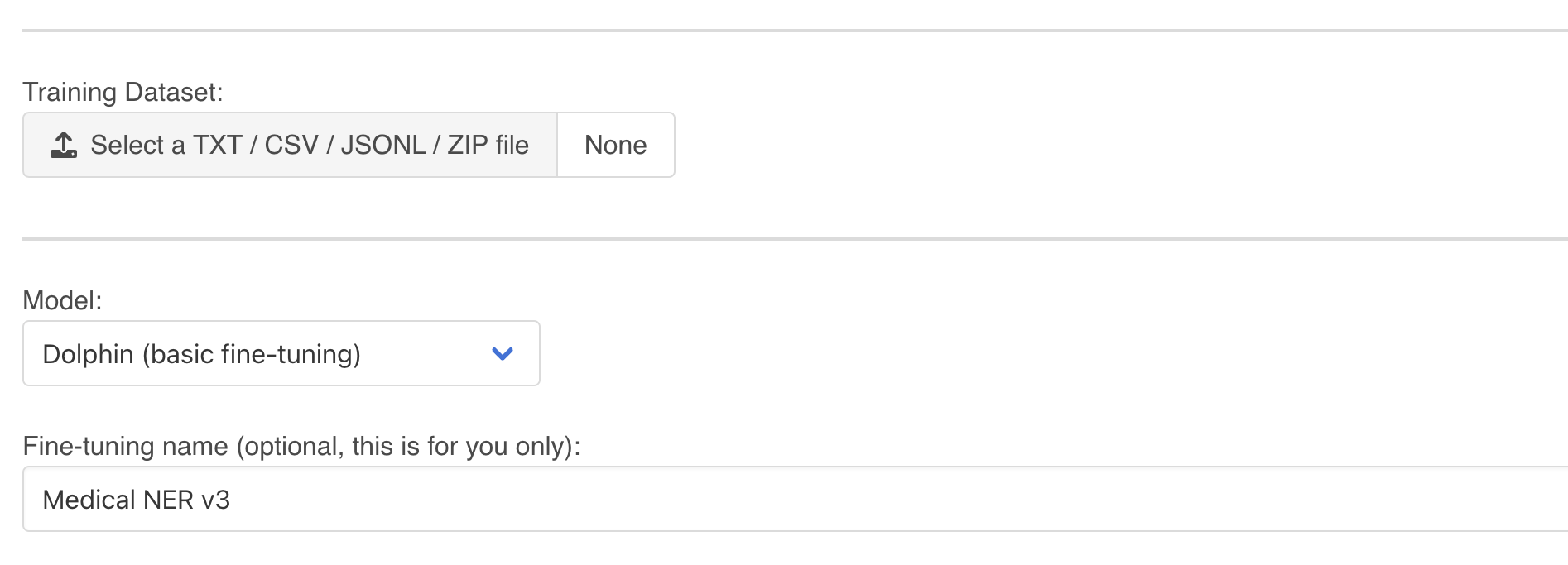
Train/Fine-Tune your own AI models with your own business data, and use them straight away in production without worrying about deployment considerations like GPU availability, memory usage, high-availability, scalability... You can upload and deploy as many models as you want into production.
Already have an account? Send us a message from your dashboard.
Otherwise, send us an email to [email protected].
We also provide advanced expertise around AI (consultancy, training, integration...). Feel free to tell us more about your project.

NLP Cloud places the safety of your data and privacy as a major concern. To guarantee the platform and data stay safe, we continuously deploy our resources and methods into our platform and methods. Mentioned below is only a portion of the security protocols we use. If you'd like to discuss how NLP Cloud can conform to your compliance requirements, please contact us!

The NLP Cloud production data is handled and held inside the most reliable cloud services and corporate data-centers.
Data that is stored for long-term use is safeguarded by being cryptographically processed.
The firewalls and secure system settings put in place protect all of the NLP Cloud servers and databases. Furthermore, Linux is the operating system that powers all of our production servers.
NLP Cloud only stores a hashed version of your password, following the PBKDF2 algorithm with a SHA256 hash.
NLP Cloud has generated extensive safety protocols touching on multiple aspects. These protocols are constantly renewed and distributed among all collaborators.
Every employee understands security protocols and regulations and participates in frequent training programs. Only a limited set of system administrators are allowed to access the NLP Cloud servers
NLP Cloud maintains regular backups of information and regularly assesses its ability to restore the data in the event of a major issue.
NLP Cloud implements strong guidelines to strike a balance between regulation and speed while changing system configurations.
We use outside security specialists to conduct thorough examinations of the NLP Cloud system.