The Power of GPT-J
Since it's been released by in June 2021, GPT-J has attracted tons of Natural Language Processing users - data scientists or developers - who believe that this powerful Natural Language Processing model will help them take their AI application to the next level (see EleutherAI's website).

EleutherAI's logo
GPT-J is so powerful because it was trained on 6 billion parameters. The consequence is that this is a very versatile model that you can use for almost any advanced Natural Language Processing use case (sentiment analysis, text classification, chatbots, translation, code generation, paraphrase generation, and much more). When properly tuned, GPT-J is so fluent that it's impossible to say that the text is generated by a machine...
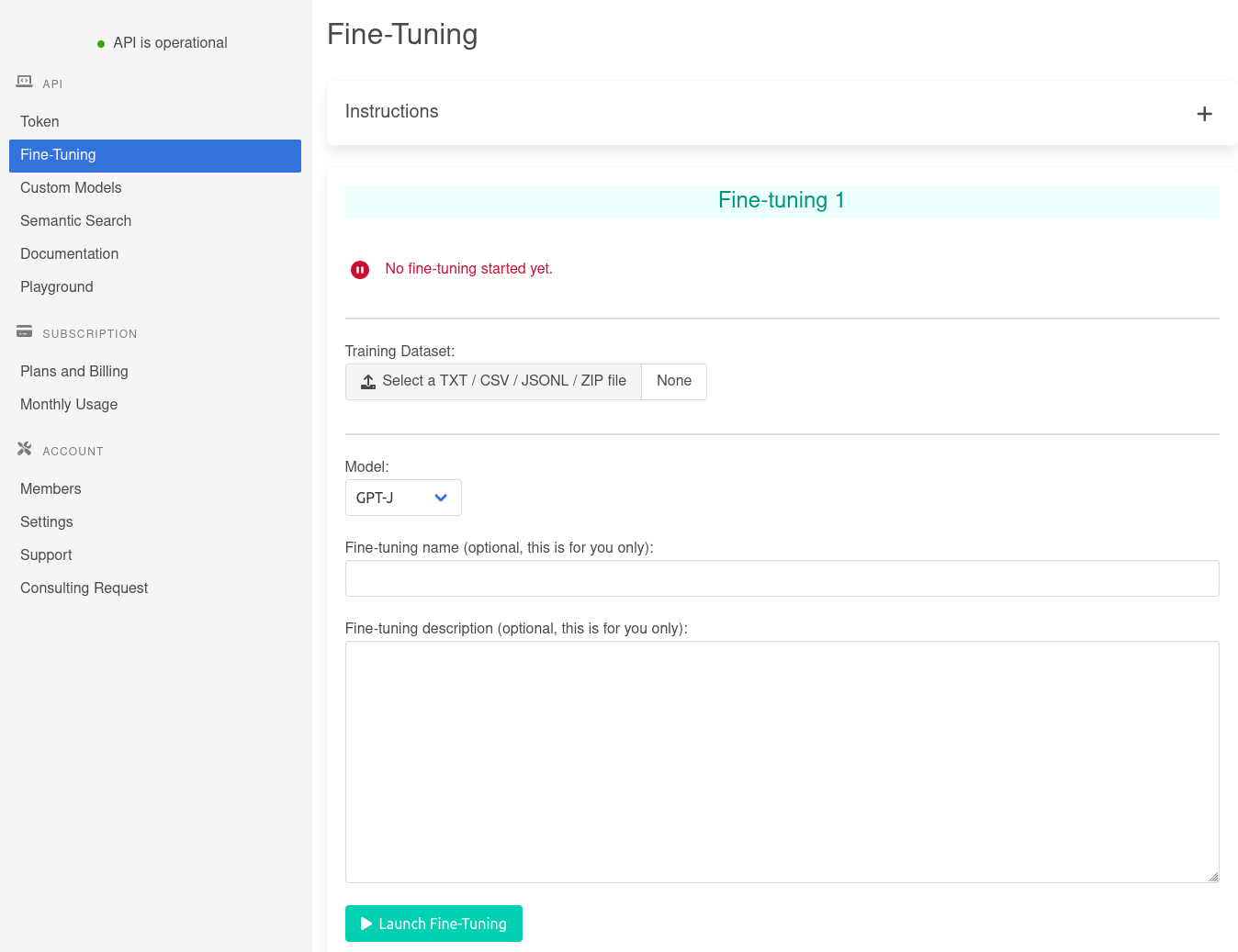
It is possible to easily adapt GPT-J to your use case on-the-fly by using the so-called technique (see how to use it here). However, if few-shot learning is not enough, you need to go for a more advanced technique: fine-tuning.