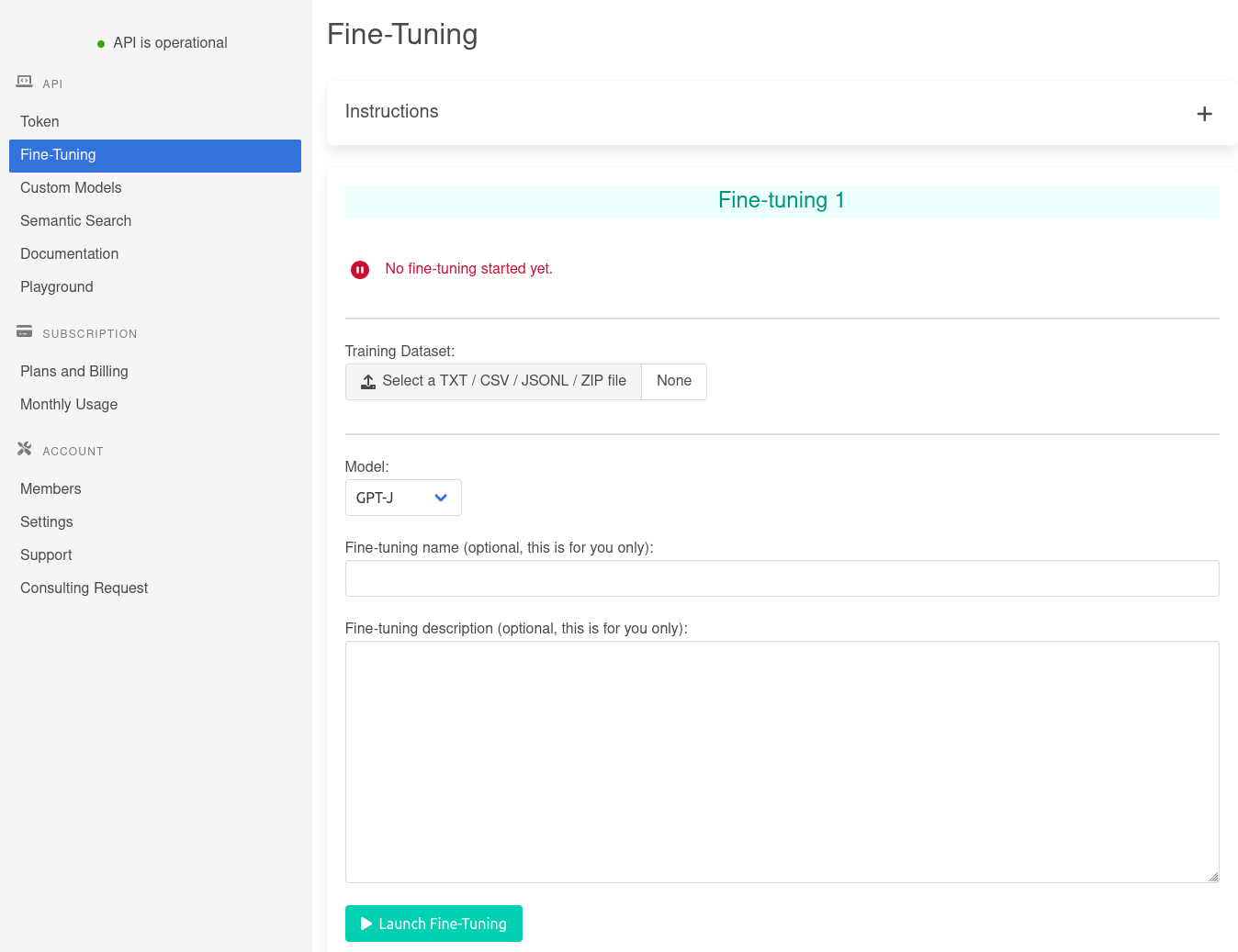
Sila GPT-J
Od svojho vydania v júni 2021 prilákal GPT-J množstvo používateľov spracovania prirodzeného jazyka - dátových vedcov alebo vývojárov - ktorí veria, že tento výkonný model spracovania prirodzeného jazyka im pomôže posunúť ich aplikáciu umelej inteligencie na vyššiu úroveň ďalšiu úroveň (pozrite si webovú stránku EleutherAI).

Logo EleutherAI
GPT-J je taký výkonný, pretože bol vycvičený na 6 miliardách parametrov. Dôsledkom toho je, že je to veľmi všestranný model, ktorý môžete použiť na takmer akýkoľvek pokročilý prípad použitia spracovania prirodzeného jazyka (analýza sentimentu, analýza textu, analýza klasifikácia, chatboty, preklad, generovanie kódu, generovanie parafráz a mnoho ďalších). Keď je správne vyladený, GPT-J je taký plynulý, že nie je možné povedať, že text je generovaný strojom...
GPT-J je možné ľahko prispôsobiť vášmu prípadu použitia za chodu pomocou tzv. techniky (pozrite si, ako ho používať, tu). Ak sa však učenie s niekoľkými zábermi stačí, je potrebné prejsť na pokročilejšiu techniku: jemné ladenie.